Marketing Mix Modelling (MMM) is a method that helps quantify the impact of several marketing inputs on sales or market share. the purpose of MMM is to understand how much each marketing input contributes to sales, and how much to spend on each marketing input.
MMM relies on statistical analysis such as multivariate regressions on sales and marketing time series data to estimate the impact of various marketing tactics (marketing mix) on sales and then forecast the impact of future sets of tactics. It is often used to optimize the advertising mix and promotional tactics with respect to sales and profits.
Marketing Mix Modeling (MMM) is one of the most popular analysis under Marketing Analytics which helps organisations in estimating the effects of spent on different advertising channels (TV, Radio, Print, Online Ads etc) as well as other factors (price, competition, weather, inflation, unemployment) on sales. In simple words, it helps companies in optimizing their marketing investments which they spent in different marketing mediums (both online and offline).
Uses of Marketing Mix Modeling
It answers the following questions which management generally wants to know.
- Which marketing medium (TV, radio, print, online ads) returns maximum return (ROI)?
- How much to spend on marketing activities to increase sales by some percent (15%)?
- Predict sales in future from investment spent on marketing activities
- Identifying Key drivers of sales (including marketing mediums, price, competition, weather and macro-economic factors)
- How to optimize marketing spend?
- Is online marketing medium better than offline?
| Types
of Marketing Mediums |
| Let's break it
into two parts - offline and online.
|
|
Offline Marketing
|
Online Marketing
|
| Print Media : Newspaper, Magazine |
Search
Engine Marketing like Content Marketing, Backlink building etc. |
| TV |
Pay
per Click, Pay per Impression |
| Radio |
Email
Marketing |
| Out-of-home (OOH) Advertising like Billboards, ads in public
places. |
Social
Media Marketing (Facebook, YouTube, Instagram, LinkedIn Ads) |
| Direct Mail like catalogs, letters |
Affiliate
Marketing
|
| Telemarketing |
|
| Below The Line Promotions like free product samples or vouchers |
|
| Sponsorship |
|
Marketing Spend as a percent of companies revenues by industry
Marketing Mix Modeling
MMM has had a place in marketers’ analytics toolkit for decades. This is due to the unique insights marketing mix models can provide. By leveraging regression analysis, MMM provides a “top down” view into the marketing landscape and the high-level insights that indicate where media is driving the most impact.
For example: by gathering long-term, aggregate data over several months, marketers can identify the mediums consumers engage with the most. MMM provides a report of where and when media is engaged over a long stretch of time.
Background: Marketing Mix Modeling (MMM)
The beginning of the offline measurement
Marketing Mix Modelling is a decades-old process developed in the earliest data of modern marketing that applies regression analysis to historical sales data to analyse the effects of changing marketing activities. Many marketers still use MMM for top-level media planning and budgeting; it delivers a broad view into variables both inside and outside of the marketer's control.
Some of the factors are:
- Price
- Promotions
- Competitor Activity
- Media Activity
- Economic Conditions
Analytical and Statistical Methods used to quantify the effect of media and marketing efforts on a product's performance is called Marketing Mix Modeling
"It helps to maximize investment and grow ROI"
ROI = (Incremental returns from investment) / Cost of Investment
Marketing ROI = (Incremental Dollar Sales from Marketing Investment) / Spend on Marketing Investment
Why is MMM Needed? Guiding Decisions for Improved Effectiveness
- How do I change the mix to increase sales with my existing budget?
- Where am I over-spending or under-spending?
- Which marketing channels are effective but lack the efficiency for positive ROI?
- To what degree do non-marketing factors influence sales?
How does MMM work?
- Correlate marketing to sales
- Factor in lag time
- Test interaction effects
- Attribute sales by input
- Model to most predictive
- Maximize significance - to empower decisions
Example Marketing Mix Model Output
Detailed output includes:
- Weekly sales lift
- More marketing channels
- Contribution by tactic
- Contribution by campaign
- Non-Marketing impact
Market Contribution vs. Base
ROI Assessment:
We measure ROI because not all ads will convert to sales, but because they are cost-effective and most bang for the buck
MMM Strengths:
- Complete set of marketing tactics
- Impact of non-marketing factors
- High Statistical Reliability
- Guides change in the marketing mix
- Guides change in spend
- Optimizes budget allocation
MMM Limitations:
- More Tactical than Strategic
- Short-Term impact only
- Dependant on variance over time
- Average Effectiveness
- No diagnostics to improve
- Hard to refresh frequently
Critical Success Factors of MMM:
- Use a Strategic approach (not tactical)
- Disclose gaps and limitations
- Add Diagnostic measures
- Integrate into robust measurement plan
- Make marketing more measurable
- Create ROI simulation tools
Media Mix Modeling as Econometric Modeling:
Strengths:
- It reduces the biases
- It correctly or accurately isolates the impact of media on sales from the impact of all other factors that influence sales.
Weaknesses:
- If two types of media are highly correlated in the historical record, then isolating and separating each media type on sales gets reduced.
For working with Market Mix Modeling - a good understanding of econometrics types of modelling is needed
The objective before starting this approach is how can we maximize the value and minimize the harm of marketing mix models like store-based models or shopper based multi-user attribution models.
Marketing End Users are the root of the cause of marketing mix models problems.
Tip: Most attribution projects begin long after the strategy has already been set. So it's important to understand what the client did, why they did it, and what they expected to happen. Only then can you answer their questions in a way they'll be happy with. Remember they hired you because the results weren't what they expected... or because they never thought about how to measure them in the first place.
As we all know weekly variation is the lifeblood of marketing mix models.
Some of the problems are continuity bias
Very interesting article on using Market Mix Modelling during COVID-19.
Market Mix Modeling (MMM) in times of Covid-19 | by Ridhima Kumar | Aryma Labs | Medium
In the model, i read that there will be sudden demand of essential items during the pandemic, but this deviance cannot be attributed to existing advertisement factors.
In the regression model we can see that there will be;
- Heteroscedasticity: The sales trend could show significant changes from the beginning to end of the series. Hence, the model could have heteroscedasticity. One of the reasons for heteroscedasticity is presence of outliers in the data or due to large range between the largest and smallest observed value.
- Autocorrelation: Also, the model could show signs of autocorrelation due to missing independent variable (the missing variable being Covid-19 variable).
Another very interesting article on Marketing Analytics using Markov chain
Marketing Analytics through Markov Chain | LinkedIn
In the article, I read that how we can use transition matrix to understand the change in states. It explains very neatly.
Article on Conjoint Analysis : Conjoint Analysis: What type of chocolates do the Indian customers prefer? | LinkedIn
Marketing Mix Modeling (MMM) is the use of statistical analysis to
estimate the past impact and predict the future impact of various
marketing tactics on sales. Your Marketing Mix Modeling project
needs to have goals, just like your marketing campaigns.
The main goal of any Marketing Mix Modeling project is to measure
past marketing performance so you can use it to improve future
Marketing Return on Investment (MROI).
The insights you gain
from your project can help you reallocate your marketing budget
across your tactics, products, segments, time and markets for a
better future return. All of the marketing tactics you use should be
included in your project, assuming there is high-quality data with
sufficient time, product, demographic, and/or market variability.
Each project has four distinct phases, starting with data collection
and ending with optimization of future strategies. Let’s take a look
at each phase in depth:
Phase 1 : Data Collection and Integrity : It can be tempting to request as much data as possible, but it's important to note that every request has a very real cost to the client. In this case the task could be simplified down to just marketing spend by day, by channel, as well as sales revenue.
Phase 2 : Modeling: Before modelling we need to;
- Identify Baseline and Incremental Sales
- Identify Drivers of Sales
- Identify Drivers of Growth
- Understanding Brand Context: Understanding the clients marketing strategy & its implementation is key for succeeding in the delivery of the MMM project.
- The STP Strategy (Segmentation, Targeting and Positioning) impacts the choice of the target audience and influences the interpretation of the model results.
- The company context and 4P's determine the key datasets that needed to be collected and influence the key factors. Eg: Impact of Seasonality , Distribution of Channels
Phase 3 : Model-Based Business MeasuresPhase 4 : Optimization & Strategies
Pitfalls in Market Mix Modeling:
1. Why MMX vendors being “personally objective” is not the same as their being “statistically unbiased”.2. How to clear the distortions that come from viewing “today’s personalized continuity marketing” through “yesterday’s mass-market near-term focused lens”.
3. Why “statistically controlling” for a variable (seasonality, trend, etc.) does NOT mean removing its influence on marketing performance.
Some points about Marketing Mix Modeling:
Your Marketing Return on Investment (MROI) will be a key metric
to look at during your Marketing Mix Modeling project, whether that
be Marginal Marketing Return on Investment for future planning or
Average Marketing Return on Investment for past interpretation. The
best projects also gauge the quality of their marketing mix model,
using Mean Absolute Percent Error (MAPE) and R^2
1. Ad creative is very important to your sales top line and your
MROI, especially if you can tailor it to a segmented audience.
This paper presents five best Spanish language creative practices
to drive MROI, which should also impact top-of-the-funnel
marketing measures.
2. The long-term impact of marketing on sales is hard to nail down,
but we have found that ads that don’t generate sales lift in the near-term usually don’t in the long-term either. You can also expect long-term Marketing Return on Investment to be about 1.5 to 2.5 times
the near-term Marketing Return on Investment.
3. Modeled sales may not be equivalent to total sales. Understand how
marketing to targeted segments will be modeled.
4. Brand size matters. As most brand managers know firsthand,
the economics of advertisement favors large brands over small
brands. The same brand TV expenditure and TV lift produces larger
incremental margin dollars, and thus larger Marketing Return on
Investment, for the large brand than the small brand.
5. One media’s Marketing Return on Investment does not dominate consistently. Since flighting, media weight, targeted audience,
timing, copy and geographic execution vary by media for a brand,
each media’s Marketing Return on Investment can also vary
significantly.
Some more background into Marketing Mix Models:
Product : A product can be either a tangible product or an intangible service that meets a specific customer need or demand
Price : Price is the actual amount the customer is expected to pay for the product
Promotion : Promotion includes marketing communication strategies like advertising, offers, public relations etc.
Place : Place refers to where a company sells their product and how it delivers the product to the market.
Marketing Objectives:
For the different marketing types: TV, Radio, Print, Outdoor, Internet, Search Engine, Mobile Apps. We would like to
1. Measure ROI by media type
2. Simulate alternative media plans
Research Objectives:
1. Measure ROI by media type
2. Simulate alternative media plans
3. Build a User-Friendly simulation tool
4. Build User-Friendly optimization tool
First Step: Building the Modeling Data Set
- Cross-Sectional Unit :
- Regions
- Markets
- Trade Spaces
- Channels
- Your brands
- Competitor brands
- At least 5 years of monthly data
- At least 2 years of weekly data
Define the Variables
Sales
- Dependent Variables
- units(not currency)
Media Variables:
- TV, Radio, Internet, Social, etc.
- Measure as units of activity (e.g., GRPs, impressions)
Control Variables
- Macroeconomic factors
- Seasonality
- Price
- Trade Promotions
- Retail Promotions
- Competitor Activity
Pick Functional Form of Demand Equation
Quantity Demanded = f
- Conditions:
- Price
- Economic Conditions
- Size of Market
- Customer Preferences
- Strength of Competition
- Marketing Activity
Most Common Functional Forms
- Linear
- Log-Linear - strong assumptions
- Double Log - more strong assumptions (used by a large percentage of models)
Modelling Issues
- Omitted Variables ( try to get as many variables as possible which are considered to have big impact on demand)
- Endogeneity Bias (Instrumental variable approach, if the variable is in our predictor variable and also in our dependant variable, this creates bias and we need to account for the bias)
- Serial Correlation (all-time series data have serial correlation which creates bias)
- Counterintuitive results ( time series is short, we may not have enough data to look back, then we try to go more cross-sectional variables in more granular)
- Short Time Series
Market-Mix Modeling Econometrics
- Mixed Modeling: fixed effects, random effects
- Parks Estimator
- Bayesian Methods: Random effects
- Adstock variables: can be split up into multiple variables for different types of advertisements like promotion, equity, etc.
Multiple Factors that Affect Outcome (Incremental Sales) :
- Campaign
- Pricing
- Other Campaigns
- Competitor Effects
- Seasonality
- Regulatory Factors
Market Mix modelling: is designed to pick up short term effects, it is not able to model long term effects such as the effect of the brand. Advertisement helps in making a brand but this is difficult to model.
Attribution Modeling: is different Media/Market Mix Modeling as it offers additional insight. In this type of modelling, we measure the contribution of earlier touchpoints of customer digital journey to final sale. Attribution Modeling is bottom-up approach but will be difficult to do because third party cookies are getting phased out
Multi-Touch Attribution modelling is more advanced than top-down Market Mix Modeling because there is an instant feed loop to understand what is working. whereas in Market Mix Modeling we would just determine the percentage of x change to drive sales and then in next year model we will do the adjustment again, without getting any real on the ground feedback to understand that whether we reached the target that we set out to achieve.
Nielson Marketing Mix Modeling is the largest Market Mix Modeling provider in the world.
The Pros and Cons of Marketing Mix Modeling
When it comes to initial marketing strategy or understanding external factors that can influence the success of a campaign, marketing mix modeling shines. Given the fact that MMM leverages long-term data collection to provide its insights, marketers measure the impact of holidays, seasonality, weather, band authority, etc. and their impact on overall marketing success.
As consumers engage with brands across a variety of print, digital, and broadcast channels, marketers need to understand how each touchpoint drives consumers toward conversion. Simply put, marketers need measurements at the person-level that can measure an individual consumer’s engagement across the entire customer journey in order to tailor marketing efforts accordingly.
Unfortunately, marketing mix modeling can’t provide this level of insight. While MMM has a variety of pros and cons, the biggest pitfall of MMM is its inability to keep up with the trends, changes, and online and offline media optimization opportunities for marketing efforts in-campaign.
]]>





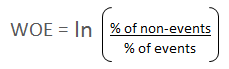
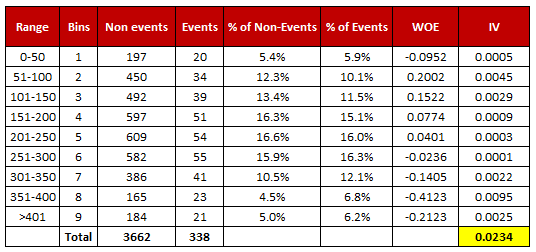














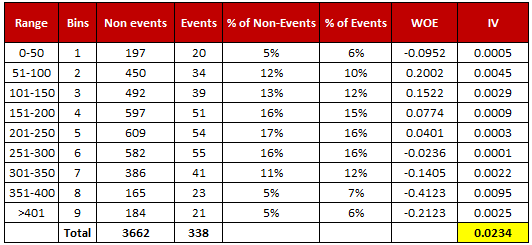{kind=link}